Hash |
您所在的位置:网站首页 › 列表法 函数 › Hash |
Hash
|
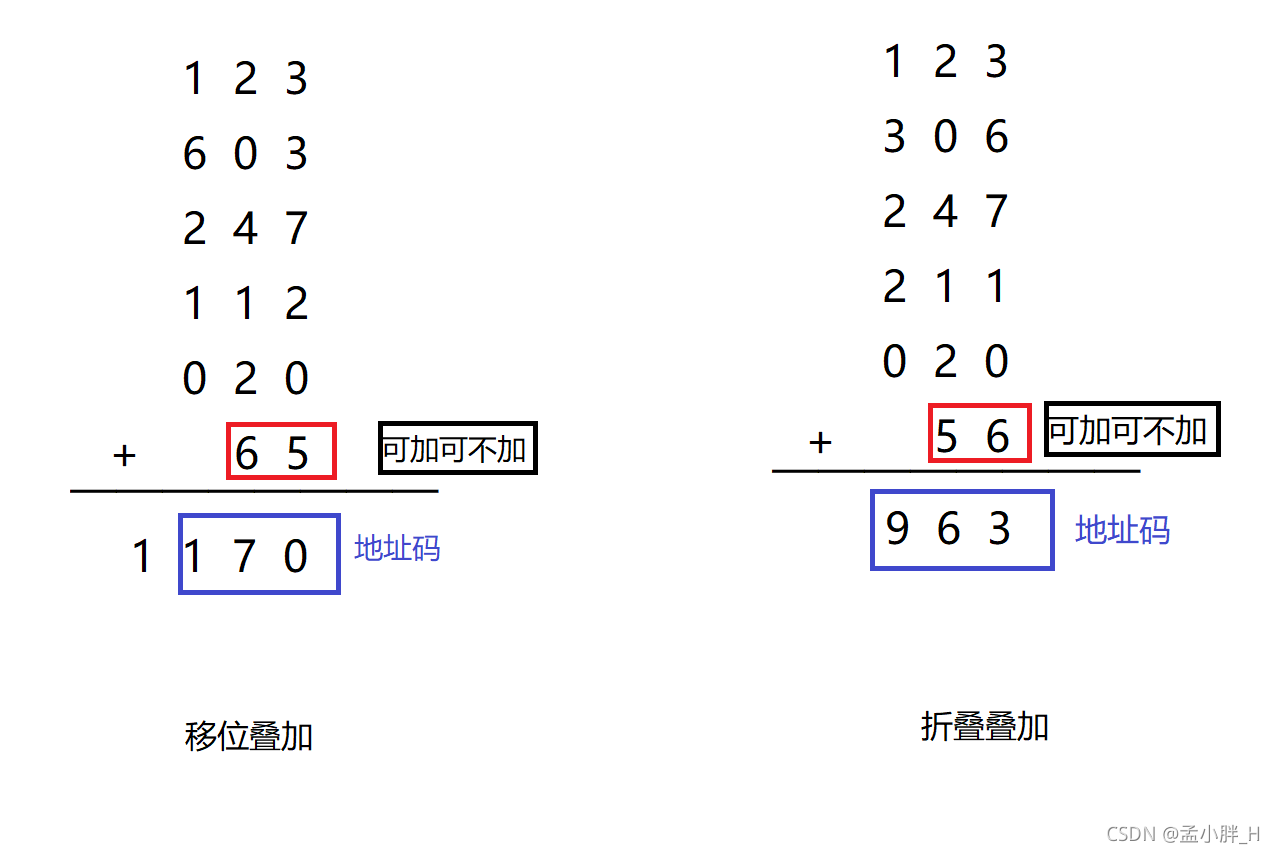
声明:本篇博客根据回顾老师上课知识和书籍《数据结构——用C语言描述》(耿国华)整理得出,仅作知识回顾学习用。 1.哈希法哈希法又称散列法、杂凑法、关键字地址计算法。相对应的表称为哈希表、散列表、或杂凑表等。 哈希方法思想: 首先在元素的关键字k和元素的存储位置p之间建立一个对应关系H,使得 p = H(k),H成为哈希函数。创建哈希表时,把关键字为k的元素直接存入地址为H(k)的单元,以后查找关键字为k的元素时,再利用哈希函数计算该元素的存储位置。再按关键字存取元素。Hash中存储的key值都是唯一的。 哈希冲突: 当关键字集合很大的时候,关键字值不同的元素可能会映射到哈希表的同一个地址,即k1 != k2,H(k1) == H(k2),这种现象称为冲突,此时k1和k2为同义词。事实上冲突是不可避免的,由于关键字可能发生冲突的集合远远大于实际开辟的哈希表长度 ,构成冲突的必然性,可通过改进哈希的性能来减少冲突,即降低冲突的可能性。 2.哈希函数的构造方法构造哈希函数原则: (1)函数本身便于计算 (2)计算出来的地址分布均匀,即对应任意一个关键字k,H(k)对应的不同地址的概率应该相同,以尽可能减少冲突 在实际应用中,构造哈希函数要考虑以下五个因素: (1)计算哈希函数所需要的时间。哈希函数一定要简单,取放key值都需要根据哈希函数和key值计算位置,计算是要花时间的,尽可能要计算简单一点,这样计算时间也会少。 (2)关键字的长度。关键字过长,我们可以考虑取关键的某几位来建立哈希函数。 (3)哈希表的大小。哈希表可以减少查找次数,但是哈希表过短,或者过长都会使哈希法性能降低。 (4)关键字分布情况。为了使key值和哈希函数计算出来的地址分布均匀,要考虑关键字分布情况建立合适哈希函数。 (5)记录查找的频率。 2.1数字分析法方法: 首先大概了解关键字集合。如果每个关键字的位数比哈希表的地址码位数多时,可以从key值选择分布均匀的若干位,构成哈希地址。 比如哈希表长度为100,即地址空间为0~99,如果有200个key值,且key值都是8位十进制数d1d2d3d4d5d6d7d8,那么我们可以选择分布较均匀的两位数字作为key值。比如说所有key中,第二位和第五位数字都分布较均匀(即200个key值的第二位第五位都比较随机),那么我们就取d2d5作为key值地址码,比如 34982748,地址码为42。 (在这里存在不相同的key值,但是地址码一样,这是哈希冲突,哈希冲突解决办法在最后给出。哈希表,一个地址码可以代表(存放)一组数据)。 2.2平方取中法方法: 当无法确定关键字中哪几位分布较均匀时,可以求出关键字的平方值,再结合哈希表长度,取平方值的中间几位作为哈希地址(比如哈希表长度是 100,那哈希地址就00-99,我们就取key值平方后的中间2位作为地址码;如果哈希表长度是1000,那么哈希地址可以是000-999,那么就取key值平方后的中间3位作为地址码)。这是因为完成平方运算后,中间几位和关键字的每一位都相关,所以不同关键字会以较高的概率产生不同的哈希地址。 2.3分段叠加法按哈希表地址位数将关键字分成位数相等的几部分(最后一部分可以较短),然后将这些部分相加,舍弃最高进位,剩下的数字作为地址码。比如哈希表长度为1000,可以表示地址码000-999。我们就把key值分成三位数为一部分。具体折叠方法有移位法和折叠法。以为叠加法直接将每一部分相加。折叠叠加法是将奇数段和偶数段分开,奇数段(偶数段)正常,偶数段(奇数段)倒序,再相加。 举例:12360324711202065
顾名思义,即对key值进行取余。看有多少key值,如果有几十个key值,我们可以选择对10取余,对15取余,等等。余数就是对应的地址码。 其实不论什么方法,目的都是为了在保证哈希函数尽可能简单的情况下让key值计算出来的地址码尽可能均匀。即让哈希表起到提高查找效率的作用。所以不管什么方法,只要达到最终这个目的就行。 2.5伪随机数法即用一个为随机函数作为哈希函数p = H(key) = random(key)。 3.处理冲突的方法 3.1开放定址法也叫做再散列法。 思想:当关键字key的初始哈希地址p0 = H(key)出现冲突时(即该地址有key值了),以p0为基础,产生另一个地址p1,如果p1仍然冲突,再以p0为基础,产生另一个哈希地址p2…直至找到一个不冲突的地址pi,将key值存到里面。 即hi = (h0 + di)%m m为表长,m为增量序列 (1)线性探测再散列 di = 1,2,3,4,…,m-1 (2)二次探测再散列 di = 1^2, -1^2, 2^2, -2^2,…, k^2, -k^2(k DataType key; KeyNode* next; }KeyNode;//key以这种结点方式被连接 typedef struct Node { int addcode;//地址码(0,1,2,3,...,9) KeyNode* next;//指向KeyNode类型的结点 }List;//哈希表每个格子的结构 typedef struct Hash { List* hash_table[TABLESIZE]; }ListHash;//哈希表 |
【本文地址】